Are Multi-step Agents Overthinking?
Since R1, the dominant trend in post-training has been longer reasoning traces. For single-step tasks — math, code, QA — this works well. These are fully observable bandit problems: the model sees everything it needs upfront, and longer chain-of-thought helps it reconstruct and cross-reference information. More thinking, better answers.
But most real-world problems are not single-step. Web navigation, device control, tool use — these require many sequentially impactful decisions before a final reward is obtained. The right abstraction is an MDP, not a bandit. This raises a question that, as far as we can tell, has not been carefully examined:
Does the “think longer” paradigm from single-step post-training actually help in multi-step environments? Or are these agents spending tokens on reasoning when they should be spending steps on acting?
The Case for Overthinking
过度思考的论据
The key structural difference between single-step and multi-step tasks is partial observability across steps. After making a decision, the agent receives genuinely new information — information that was impossible to derive from reasoning alone, no matter how long the chain of thought. Before acquiring this information, the agent should not commit to an answer. And crucially, the action needed to acquire it is often trivial.
Consider a web agent that needs to find a website meeting several requirements. These requirements can only be verified after clicking into the site. Before visiting, no amount of reasoning can determine whether the site qualifies. The agent must click in, check, click out, and try the next candidate. The optimal strategy involves almost no reasoning — just systematic exploration.
This suggests a possible failure mode: an agent post-trained on single-step tasks learns that long reasoning traces correlate with success. Deployed in a multi-step environment, it applies the same strategy — thinking extensively before each action. But if the information it needs is locked behind environment interactions, thinking is not a substitute for acting. The agent would be, in a precise sense, overthinking.
Is this what actually happens?
What the Experiments Show
实验结果
We trained agents on multi-step web tasks under different training configurations and found patterns consistent with the overthinking hypothesis:
Observation 1: Long horizons, poor performance. With a train-time horizon of \(h = 30\), the agent produces long trajectories but achieves weak task success. One explanation: REINFORCE suffers from error accumulation over many steps. Even successful trajectories contain suboptimal actions that the agent cannot reliably reproduce at evaluation time. But another reading is that the long horizon gives the agent room to deliberate excessively at each step, compounding reasoning errors across the trajectory.
Observation 2: Short horizons help — up to a point. With \(h = 10\), performance improves substantially. The agent is forced to be decisive. But trajectory length shrinks over training. The agent learns to declare success prematurely rather than explore further. It stops overthinking, but it also stops acting — giving up on complex tasks that require information gathering across many pages.
Observation 3: No fixed horizon is satisfactory. A fixed intermediate value (\(h = 20\)) inherits both problems: it’s too generous for simple tasks (allowing overthinking) and too restrictive for hard tasks (preventing exploration). It also requires task-specific tuning, undermining scalability.
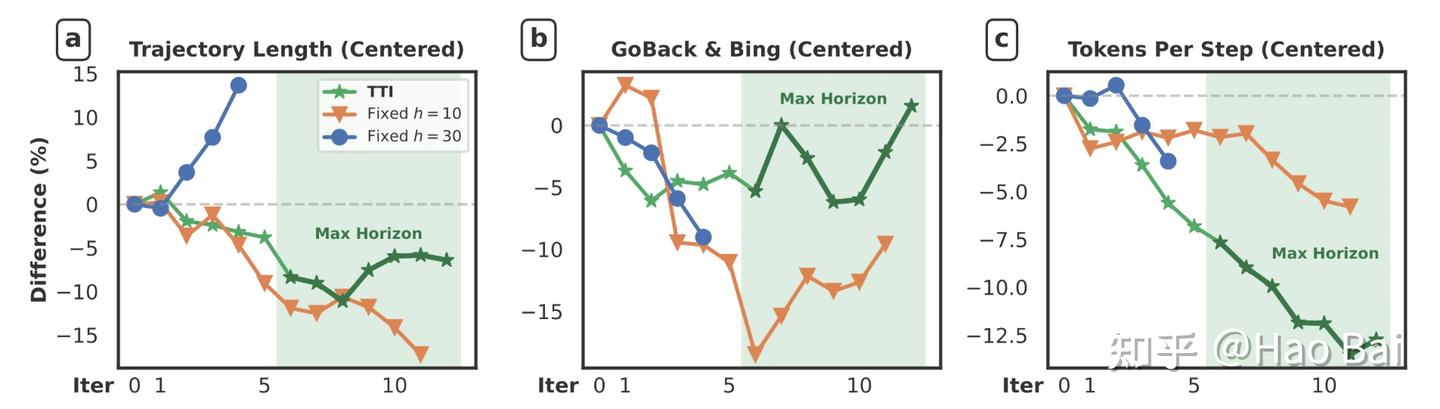
The three plots above are suggestive. Each has three lines; our method (TTI) is green. Once the maximum horizon is reached: (a) average trajectory length grows — the agent takes more actions; (b) information-gathering frequency increases — the agent navigates back and jumps to search engines more often; (c) reasoning token count drops rapidly — the agent thinks less.
If overthinking were not a real phenomenon, we would not expect to see reasoning length decrease as performance increases. Yet that is exactly what happens.
A Simple Intervention: Horizon Curriculum
一个简单的干预方法:Horizon 课程学习
If agents are indeed overthinking, what can we do about it? Rather than explicitly constraining reasoning length (which would be a brittle, task-specific fix), we tested whether the training dynamics alone could teach the agent to reason less.
The idea is a horizon curriculum — start small and grow:
- Begin with a short horizon (\(h = 10\)). The agent learns basic environment dynamics and solves easy tasks, where extended reasoning was never necessary.
- Gradually increase the horizon (\(10 \to 20 \to 30\)). The agent encounters progressively harder tasks requiring genuine multi-step exploration. Because it already learned to act efficiently at shorter horizons, it extends that efficient behavior rather than regressing into overthinking.
We call this Test-Time Interaction (TTI). The curriculum forces the agent to build good habits early — act quickly, gather information, don’t speculate — and then applies those habits to harder problems.
The striking finding is that TTI imposes no constraints on chain-of-thought length. The reduction in reasoning emerges entirely from the training dynamics. The agent discovers on its own that shorter thinking and more actions is the better strategy. This emergent property is important: it suggests the overthinking problem is real and that the agent can learn to correct it, given the right training structure.
Results
结果
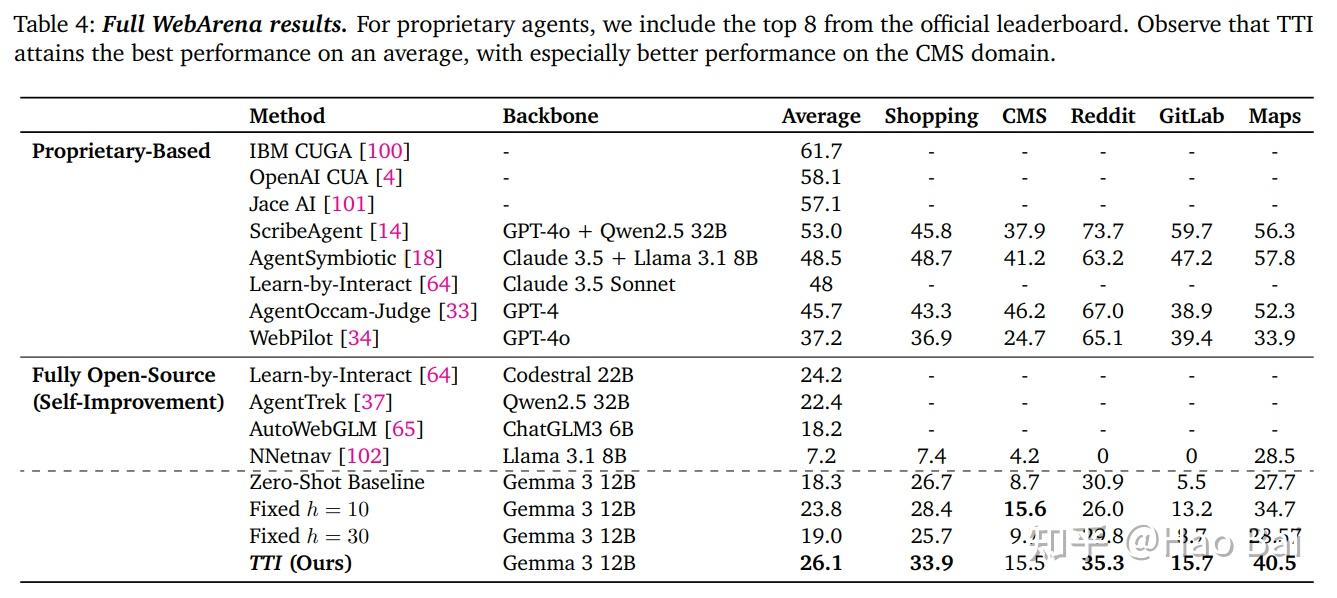
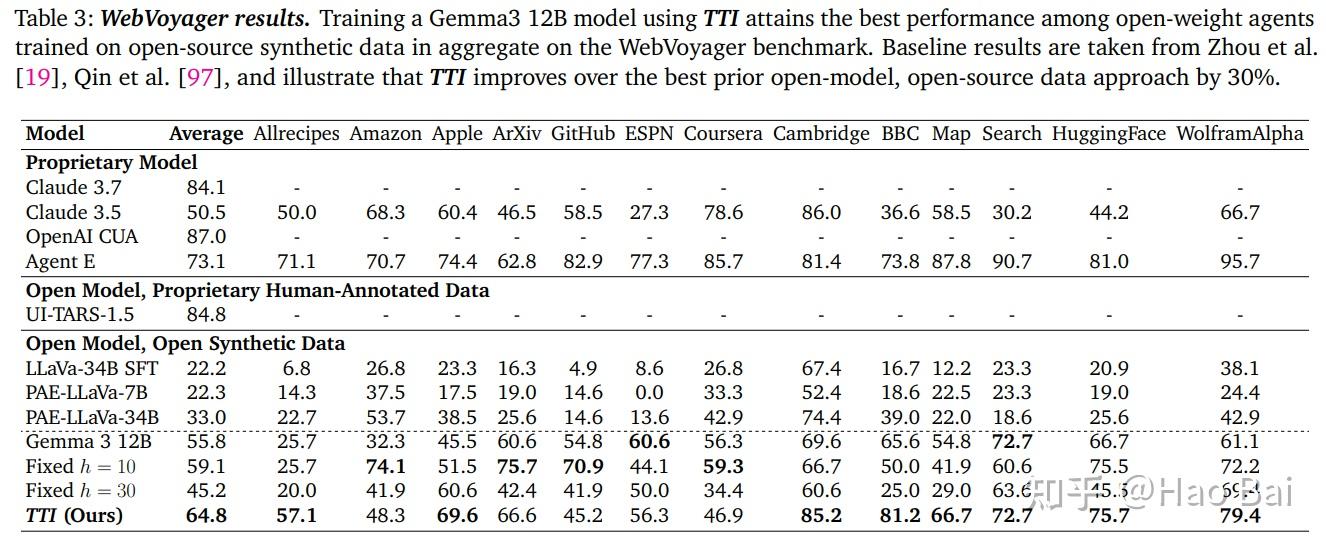
TTI outperforms both fixed-short and fixed-long horizons on WebVoyager and WebArena. The performance gains correlate with the agent learning to reallocate its compute budget: less internal reasoning per step, more environment interaction overall.
How General Is This?
这一现象有多普遍?
The overthinking hypothesis, if correct, should apply beyond web agents. Any multi-step setting where the environment provides information that cannot be derived internally would exhibit it: robotics (try a grasp instead of planning it perfectly), tool use (call the API instead of predicting its output), dialogue (ask a clarifying question instead of guessing the user’s intent).
The common thread is that in these settings, the environment is a better source of information than the model’s own reasoning. An agent that recognizes this should think just enough to choose a reasonable next action, then act and observe. The optimal reasoning length per step may actually decrease with better training, as the agent learns to offload cognitive work to the environment.
Whether this pattern holds across domains — and whether the horizon curriculum is the right intervention in all cases — remains to be tested. But the evidence from web tasks is consistent with a simple thesis: multi-step agents trained with standard methods are spending too many tokens thinking and too few steps acting.
Takeaway. There is growing evidence that multi-step agents inherit a “think longer” bias from single-step post-training that actively hurts them. A simple horizon curriculum (short → long) lets the agent discover on its own that less reasoning and more interaction leads to better outcomes — without any explicit constraints on chain-of-thought length.