Video Models and World Action Modeling
Video Generation: Diffusion, DiT, and Flow Matching
视频生成:扩散、DiT 与流匹配
A WAM is a video model with an action head. So before unpacking the WAM designs, this section walks through the four generative-backbone ideas that the rest of the post relies on: diffusion (the loss), the diffusion transformer (DiT) and how it gets conditioned, the split between autoregressive vs diffusion video models, and flow matching (a slightly different parameterization of the same family). Two short primers — on self-attention vs cross-attention, and on where text conditioning actually enters a DiT — are slotted in where they pay off most.
Diffusion: Iterative Denoising as Generation
扩散:以迭代去噪作为生成
The denoising diffusion probabilistic model — DDPM, Ho et al. 2020 — defines a generative process by inverting a noise-injection process. The forward process gradually corrupts data \(x_0 \sim p_{\text{data}}\) over \(T\) steps:
\[q(x_t \vert x_{t-1}) = \mathcal{N}(\sqrt{1-\beta_t}\, x_{t-1},\, \beta_t I), \qquad q(x_t \vert x_0) = \mathcal{N}(\sqrt{\bar\alpha_t}\, x_0,\, (1-\bar\alpha_t) I)\]with \(\bar\alpha_t = \prod_{s \le t}(1-\beta_s)\). As \(t \to T\), \(x_T\) becomes pure Gaussian noise. To sample, we learn to reverse this — predict the noise component \(\epsilon\) that was added at each step:
\[\mathcal{L}_{\text{DDPM}} = \mathbb{E}_{t, x_0, \epsilon}\big[\Vert \epsilon - \epsilon_\theta(x_t, t) \Vert^2\big], \qquad x_t = \sqrt{\bar\alpha_t}\, x_0 + \sqrt{1-\bar\alpha_t}\,\epsilon\]At sampling time, we start from \(x_T \sim \mathcal{N}(0, I)\) and iteratively denoise: \(x_T \to x_{T-1} \to \ldots \to x_0\). The “diffusion” name comes from the SDE / score-matching view (Song et al. 2020): the forward process is a stochastic differential equation, the reverse is a learned score \(\nabla_x \log p_t(x)\), and the generative process is integrating that score back from noise to data. The cost is sampling latency — typically 50–1000 forward passes per sample.
We can make this Markov chain concrete. The figure below traces one \(x_0 \to x_T\) trajectory using a 5×5 grid of pixels: in the forward direction, \(q\) progressively swaps blue (signal) cells for red (noise) cells until the data is gone; in the reverse direction, \(\epsilon_\theta\) is trained to undo that swap one step at a time. Toggling the two buttons swaps which formula governs the displayed direction.
The Diffusion Transformer
扩散 Transformer (DiT)
Early diffusion models used U-Nets as the denoiser. DiT (Peebles & Xie 2022) replaced the U-Net with a transformer in order to inherit ViT’s scaling properties. The paper trains class-conditional latent DiT on ImageNet — there is no text, no cross-modal alignment, no captioning; just a 1000-way class label as the conditioning signal \(c\). Within that scope, DiT systematically explores three things: how to patchify, how to inject conditioning, and how to scale.
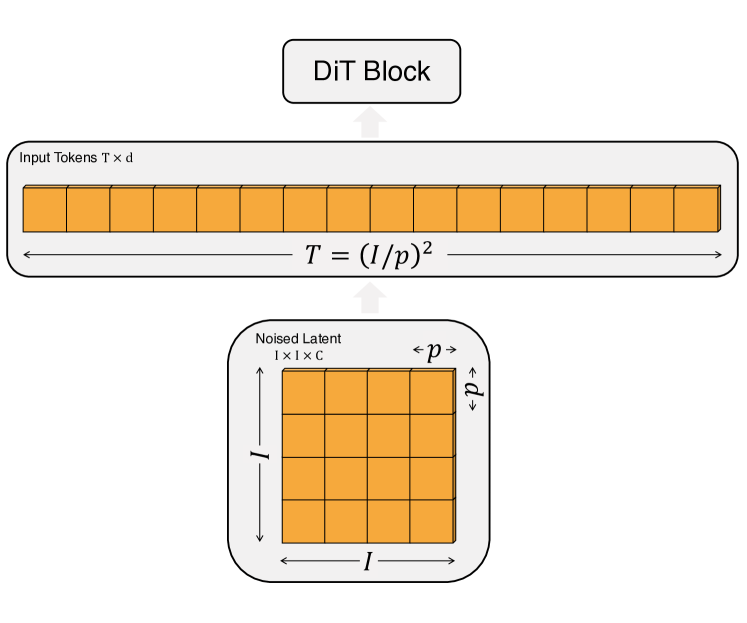
The full pipeline. A pretrained Stable-Diffusion-style VAE maps a \(256 \times 256 \times 3\) image to a \(32 \times 32 \times 4\) latent \(z = E(x)\) (downsample factor 8). DiT operates entirely in this latent space. The latent of shape \(I \times I \times C\) is patchified into a sequence of length \(T = (I/p)^2\) at hidden dim \(d\), where \(p \in \{2, 4, 8\}\) is the patch size. The token sequence is processed by \(N\) identical DiT blocks, then a final LayerNorm + linear head decodes each token back to a \(p \times p \times 2C\) tensor (noise + diagonal covariance), which is rearranged to the latent’s original spatial layout. Smaller \(p\) means more tokens, more Gflops, and — empirically — lower FID.
Encoder or decoder? Strictly, neither in the seq2seq sense. Architecturally, DiT is encoder-only (BERT / ViT-style): bidirectional self-attention, no causal mask, all latent tokens processed together, output shape = input shape. It does not autoregress. Functionally, DiT is the denoiser \(\epsilon_\theta(x_t, t, c)\) called repeatedly inside the diffusion sampling loop — input is a noised latent, output is a noise prediction. The actual encoder and decoder of the whole system are the VAE pair around DiT: the VAE encoder turns pixels into a latent before sampling starts, the VAE decoder turns the final cleaned latent back into pixels. DiT sits between them and is neither — it’s the iteratively-applied refiner.
Figure 4 of the paper visualizes the patchify operation in concrete shape terms.
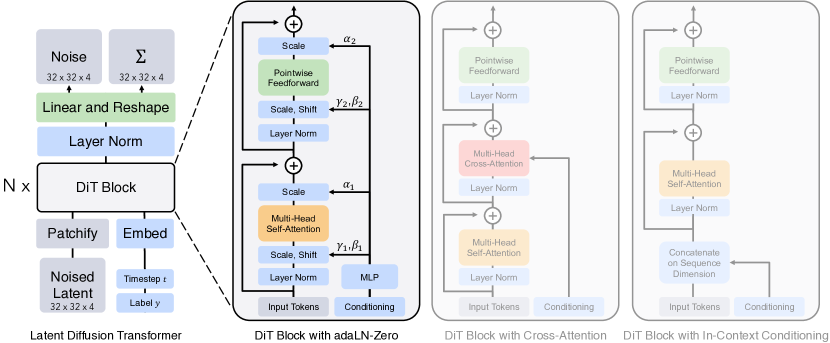
Four block designs for injecting conditioning. Once the image is a sequence of tokens, the question is how to feed the network the noise level \(t\) and the class label \(c\). The DiT paper explicitly considers four variants — these are exactly the panels on the right of Figure 3:
- In-context conditioning. Append the embeddings of \(t\) and \(c\) as two extra tokens to the input sequence (like ViT’s
[CLS]token). Let standard self-attention mix them with the image tokens; remove them after the final block. Adds essentially zero Gflops. - Cross-attention block. Concatenate \(t\) and \(c\) into a length-2 sequence, kept separate from the image tokens. Insert a multi-head cross-attention layer after the self-attention layer in each block, where image queries attend to the \((t, c)\) keys/values. This costs about 15% more Gflops than the other variants.
- adaLN block. Replace each LayerNorm in the block with adaptive LayerNorm: instead of learning the scale \(\gamma\) and shift \(\beta\) as fixed parameters, regress them from the sum of the \(t\) and \(c\) embeddings via a small MLP. The same \((\gamma, \beta)\) is broadcast to every token. Lowest Gflops of the four.
- adaLN-Zero block. Same as adaLN, but additionally regress a dimension-wise scale \(\alpha\) that multiplies each residual branch right before it is added back. Initialize the MLP so \(\alpha\) starts at zero — each block then starts as the identity function and only gradually becomes useful as training progresses, mirroring zero-init residual tricks from ResNet / U-Net training.
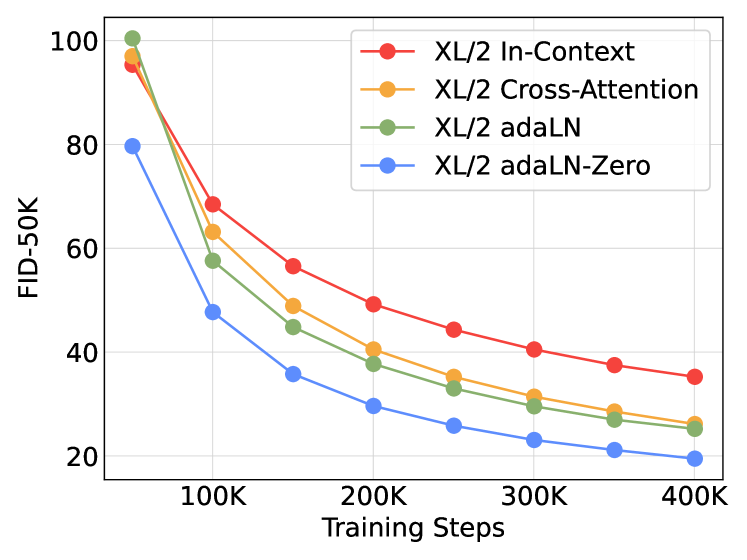
The headline empirical result (Figure 5): adaLN-Zero wins decisively on FID, despite being among the cheapest. Cross-attention costs 15% extra Gflops and is worse than adaLN-Zero. In-context conditioning is worst of all — at 400K iterations, in-context FID is roughly twice that of adaLN-Zero. So the DiT paper’s recommendation is unambiguous: pool the condition into a vector and drive adaLN-Zero with it. No cross-attention.
The figure below — Figure 3 of the paper, the most-cited DiT figure — puts the full pipeline (left) next to the four block variants (right) on one page.
And the FID curves that decided it:
The full block, written out. With the choice settled, the canonical DiT block (used in every subsequent paper that says “DiT”) is:
\[h \to h + \alpha_1 \cdot \text{Self-Attn}\big(\gamma_1 \cdot \tfrac{h - \mu(h)}{\sigma(h)} + \beta_1\big), \qquad h \to h + \alpha_2 \cdot \text{FFN}\big(\gamma_2 \cdot \tfrac{h - \mu(h)}{\sigma(h)} + \beta_2\big)\]where \((\gamma_1, \beta_1, \alpha_1, \gamma_2, \beta_2, \alpha_2) = \text{MLP}(t + c)\) and the MLP is zero-initialized so all \(\alpha\) start near zero. Note the structure: just Self-Attn → FFN, two LayerNorms replaced by adaLN, two residual scales — no cross-attention.
Scaling behavior. The paper sweeps four model configs × three patch sizes × FID at each checkpoint:
| config | layers \(N\) | hidden \(d\) | heads | Gflops ((I=32, p=4)) |
|---|---|---|---|---|
| DiT-S | 12 | 384 | 6 | 1.4 |
| DiT-B | 12 | 768 | 12 | 5.6 |
| DiT-L | 24 | 1024 | 16 | 19.7 |
| DiT-XL | 28 | 1152 | 16 | 29.1 |
The headline scaling result: Gflops, not parameter count, predict FID. Halve the patch size and parameters barely change but Gflops 4× — and FID drops just as much as if you had grown the model. DiT-XL/2 reaches FID 2.27 on class-conditional ImageNet 256×256, beating all prior diffusion models at the time.
The legacy. The adaLN-Zero block became the universal backbone of modern image / video DiTs — Stable Diffusion 3, Sora, Wan, Cosmos-Predict2.5, and the 2B Cosmos-Predict2 model that Cosmos Policy fine-tunes are all built on it. But none of these systems is just DiT: every text-to-image / text-to-video model reintroduces cross-attention as a separate layer. The reason is a structural mismatch between class labels and text.
DiT’s \(c\) is a 1000-way one-hot — a categorical variable with no internal structure. The “embed it, feed adaLN” pipeline is lossless for that kind of conditioning: a single vector carries the entire label, and broadcasting one \((\gamma, \beta, \alpha)\) tuple to every image token is exactly the right behavior when the whole image is just “a golden retriever”. A natural-language prompt is the opposite kind of object. It has position (“a red cube on a blue cube”), dependencies (“the cat that the dog is chasing”), and count (“three apples”). All of these facts live in the relative arrangement of tokens. If you pool the T5 / CLIP token sequence into a single vector and only feed adaLN, those structural facts get smeared together and the model produces images with the right vibe but the wrong content — the classic “two cats on the left, one dog on the right” prompt that comes back with the wrong counts and positions.
Cross-attention restores the missing channel: image queries attend to the unpooled text token sequence and can route information to specific spatial positions. The compromise the field converged on is a block of the form Self-Attn → Cross-Attn(text) → FFN, with all three sub-layers wrapped in adaLN-Zero modulation driven by the timestep \(t\) together with a pooled text summary. So adaLN-Zero is not replaced — it absorbs the global signal (noise level, overall style) for free, while cross-attention handles the positional and compositional parts of the text that adaLN structurally cannot represent.
Some recent designs go a step further: SD3’s MMDiT and Flux merge the text token sequence directly into the same attention as the image tokens — one big joint self-attention rather than self + cross — while still keeping per-modality adaLN-Zero modulation. But the high-level division is the same in every variant: adaLN-Zero carries the conditioning that is uniform across all spatial positions, and attention to the unpooled text carries the conditioning that is position-specific. DiT settled the first half of the recipe; modern systems added the second.
Self-Attention vs Cross-Attention: A Primer
自注意力 vs 交叉注意力:基础铺垫
The DiT discussion above keeps using self-attention and cross-attention as if they were obvious — worth a one-section reminder of how they actually differ, since the rest of this post (Cosmos’s text cross-attention, Fast-WAM’s MoT) leans on it. For the full ground-up walkthrough — single-layer attention, multi-head attention, and the encoder-decoder origin story — see the transformers post.
The mechanical difference is just where Q, K, V come from. A self-attention layer takes a single sequence \(X\) and projects it three ways: \(Q = X W^Q\), \(K = X W^K\), \(V = X W^V\). The output \(\text{softmax}(QK^\top / \sqrt{d}) V\) has the same shape as \(X\) — every token has been refined by reading every other token in the same sequence. A cross-attention layer takes two sequences: \(Q\) is projected from stream \(A\), but \(K\) and \(V\) are projected from stream \(B\). The math is identical (same softmax, same shape rule), but the output is A-shaped and is a weighted read of B. So self-attention is “tokens look at each other”; cross-attention is “stream A looks up stream B”.
Why ever use cross-attention instead of just concatenating and self-attending? Three practical reasons:
- Asymmetric flow. Self-attention is symmetric: every token influences every other token. Cross-attention is one-way — stream A reads B, but B is unchanged. That asymmetry is what you want when one stream should condition on another: an image denoiser reading a frozen T5 encoder, where you don’t want image gradients flowing back into the language model.
- Variable-length conditioning without paying \(O(N_A^2)\) on \(B\). If \(B\) is much shorter than \(A\) (a 77-token text prompt vs \(1{,}024\) image patches), full self-attention over the concatenation is \(O((N_A + N_B)^2)\), with most cells wasted on text-text or text-padding. Cross-attention is \(O(N_A \cdot N_B)\) — exactly the cells you need.
- Modality boundaries. Cross-attention keeps the two streams structurally separate: their MLPs, LayerNorms, and positional encodings can differ. Forcing them into a single self-attention requires a shared embedding space, which is awkward when the two modalities live at very different scales.
Where this shows up in this post:
- Original Transformer (encoder-decoder). The canonical example: decoder tokens read encoder output via cross-attention. (deep-dive)
- DiT. Tested cross-attention as one of four conditioning variants — with \(c\) a one-hot, it lost to adaLN-Zero (see the DiT subsection above).
- Cosmos-Predict / Cosmos Policy. Image / video tokens read T5-XXL via cross-attention; this pathway is what carries the language instruction \(\ell\) at policy fine-tuning time.
- Fast-WAM. Its Mixture-of-Transformer is a generalized cross-attention: video DiT and action expert each keep their own MLPs and norms, but attention pools both modalities’ Q / K / V so each branch reads the other.
The point is that “use cross-attention” isn’t an architectural quirk — it’s the standard answer whenever two streams should talk without merging.
Where Does Text Conditioning Live in Modern DiTs?
现代 DiT 里的文本条件注入
Neither DDPM nor DiT natively processes text. Both are denoisers that map \((x_t, t, c)\) to a noise prediction; what \(c\) is depends on the system. The original DDPM was fully unconditional. The original DiT used ImageNet’s 1000 class labels — \(c\) was a 1000-way one-hot fed through the same MLP that emits the adaLN coefficients.
So where does language come in for modern image / video diffusion? The answer is: a separate, usually frozen, text encoder. Stable Diffusion 1.5 used CLIP; SDXL used CLIP+T5; Stable Diffusion 3, Sora, and Cosmos-Predict all use T5-XXL. The text encoder turns a prompt into an embedding sequence \(\ell\), and that sequence is injected into the denoiser through one (or both) of two routes:
- adaLN / FiLM. Pool \(\ell\) to a single vector and feed it (alongside the noise level \(t\)) into the MLP that emits each block’s \((\gamma, \beta, \alpha)\). This is direct generalization of how class labels were handled in the original DiT.
- Cross-attention. Keep \(\ell\) as a sequence, and let image patches attend to it via cross-attention layers inserted into each block. This is what SD 1.5 and Sora-class models do.
SD3’s MM-DiT goes further: text and image tokens share a joint attention pool, with separate MLPs but interleaved attention.
A subtle point worth making explicit: cross-attention is not part of the recommended DiT recipe. The DiT paper did consider it — it was one of the four conditioning variants — but the empirical comparison ranked it strictly worse than adaLN-Zero (worse FID, 15% extra Gflops). For class-conditional generation, where \(c\) is a one-hot vector, that ranking is decisive: pool, drive adaLN-Zero, done. Modern text-conditional DiTs put cross-attention back into the block, not because adaLN was wrong but because text is not a one-hot. The canonical text-to-video block — used in Sora, Cosmos-Predict, Wan, and what Cosmos Policy fine-tunes — is
\[\text{adaLN-Zero} \to \text{Self-Attn} \to \text{adaLN-Zero} \to \text{Cross-Attn(text)} \to \text{adaLN-Zero} \to \text{FFN}\]with all three sub-layers wrapped by adaLN-Zero modulation driven by \(t\) (and optionally a pooled text embedding). adaLN-Zero is still the conditioning backbone; cross-attention is the additional mechanism for reading the text sequence — exactly the functionality the original DiT didn’t need because its conditioning had no sequential structure.
The conceptual point is that the denoising backbone is language-unaware. It just receives a vector of numbers. Prompt adherence improves by swapping in a smarter text encoder, not by training the diffusion model on more language. This is the structural opposite of autoregressive video models, where text and discrete video tokens live in the same vocabulary and a single decoder-only transformer attends over both jointly — no external text encoder needed. The price AR pays is sequential decoding and discrete-token quantization losses; the price diffusion pays is that “language understanding” is forever outsourced.
For Cosmos Policy, the implication is concrete: when the post-training loop reuses Cosmos-Predict2’s T5-XXL cross-attention pathway with the language instruction \(\ell\) (“pick up the red cup”), all the language understanding lives in T5-XXL — the DiT itself only sees the cross-attention output.
Two Families of Video Models: Autoregressive vs Diffusion
视频模型的两大流派:自回归 vs 扩散
A video model parameterizes \(p(z_{1:T} \vert c)\) over a sequence of frame latents \(z_t\) given conditioning \(c\). There are two dominant ways to factorize this distribution.
Autoregressive video models factorize causally:
\[p(z_{1:T} \vert c) = \prod_{t=1}^{T} p_\theta(z_t \vert z_{<t}, c)\]Each frame is generated conditioned on the previous frames. The frame latents are typically discrete tokens from a VQ-VAE. Representative works: VideoGPT (Yan et al. 2021), MAGVIT-v2 (Yu et al. 2023), VideoPoet (Kondratyuk et al. 2023). The training objective is the standard token cross-entropy. The architecture is a decoder-only transformer — the same one that backs LLMs.
Diffusion video models treat the entire clip as one tensor and denoise it jointly:
\[p_\theta(z_{1:T} \vert c) = \int \mathcal{N}(z_{1:T}^{(T_d)}; 0, I) \prod_{\tau=T_d}^{1} p_\theta(z_{1:T}^{(\tau-1)} \vert z_{1:T}^{(\tau)}, c)\, dz_{1:T}^{(T_d)}\](where \(\tau\) indexes diffusion steps, distinct from frame index \(t\)). All frames are corrupted together with noise level \(\tau\), and a DiT denoises them in parallel. Representative works: Sora (OpenAI 2024), Stable Video Diffusion (Blattmann et al. 2023), the Cosmos World Foundation Model platform (NVIDIA 2025), and Cosmos-Predict2.5.
Trade-offs.
| Autoregressive | Diffusion | |
|---|---|---|
| Frame factorization | causal, sequential | joint, parallel |
| Token type | discrete (VQ) | continuous (VAE) |
| Length | variable (extend by sampling more) | fixed (chunk-based) |
| Sampling cost | \(T\) forward passes | \(\tau\) denoising steps × 1 pass each |
| Bidirectional context | no (within frame yes, across no) | yes |
| Architecture | decoder-only LLM | DiT |
Where they meet. The line is blurring. Diffusion Forcing (Chen et al. 2024) trains a single transformer that denoises each frame at an independently sampled noise level — recovering AR generation as the limit where earlier frames have noise level 0 and later frames have noise level \(\tau\). Cosmos Policy’s “planning mode” is exactly this trick: clamp \((s, a)\) to clean and denoise \((s', V)\) — diffusion in the within-clip generative direction, autoregressive across decision steps. So in practice the modern frontier is block-autoregressive diffusion: diffuse within a chunk, autoregress between chunks.
Side-by-side, the two pipelines look very different in motion. The figure below lets you step through generation in both: try advancing the step counter and watch how AR fills exactly one frame per pass (and stops only after \(T\) passes), while diffusion gradually denoises all frames at once over a fixed number of \(\tau\) steps. The attention masks above each panel are the structural reason: a triangular mask forces causality, full attention permits joint refinement.
Flow Matching
流匹配(Flow Matching)
Flow Matching (Lipman et al. 2022) and the closely related Rectified Flow (Liu et al. 2022) take a different angle on continuous-time generative modeling. Instead of defining a stochastic forward process and learning the reverse score, flow matching defines a deterministic interpolation path from noise to data and learns its velocity.
The most common (rectified) flow path is the straight line:
\[x_t = (1 - t)\, x_0 + t\, x_1, \qquad x_0 \sim \mathcal{N}(0, I),\; x_1 \sim p_{\text{data}},\; t \in [0, 1]\]Differentiate: \(\frac{d x_t}{d t} = x_1 - x_0\). So the ground-truth velocity along this path is \(x_1 - x_0\). The flow-matching loss simply regresses a velocity network onto this:
\[\mathcal{L}_{\text{FM}} = \mathbb{E}_{t, x_0, x_1}\big[\Vert v_\theta(x_t, t) - (x_1 - x_0) \Vert^2\big]\]At sampling time, integrate the learned ODE \(\frac{dx}{dt} = v_\theta(x, t)\) from \(t=0\) (noise) to \(t=1\) (data), e.g. with Euler steps. Because the underlying paths are straight, you can integrate with very few steps — often \(5\)–\(10\) — vs hundreds for classical diffusion.
The objective looks almost identical to DDPM noise prediction, but it is actually predicting the velocity field of a probability flow, not noise. Cosmos-Predict2 and Fast-WAM both use this objective. For an extended discussion of flow matching as a generative-modeling framework — including its appearance as a policy class in deep RL — see the flow-matching-RL post.
Diffusion vs Flow Matching: Same Family, Different Path
扩散 vs 流匹配:同一家族,不同路径
The two are not rival paradigms — they are different choices on the same continuous-time generative-modeling spectrum.
Both define a process linking a tractable prior \(p_0 = \mathcal{N}(0, I)\) to a data distribution \(p_1 = p_{\text{data}}\), parameterize a network on a noisy intermediate \(x_t\), and regress a target.
Where they differ:
| Diffusion (DDPM-style) | Flow matching | |
|---|---|---|
| Forward process | stochastic SDE | deterministic interpolation |
| Path | curved (variance-preserving) | straight (rectified) or arbitrary |
| Target | noise \(\epsilon\) or score \(\nabla \log p_t\) | velocity \(v = dx/dt\) |
| Sampling | reverse SDE / ODE, many steps | ODE, few steps |
| Noise schedule | tuned (cosine, linear, …) | trivial (\(t \in [0,1]\)) |
The equivalence. Lipman et al. show that flow matching with a Gaussian probability path recovers score-based diffusion as a special case — DDPM’s \(x_t = \sqrt{\bar\alpha_t} x_0 + \sqrt{1-\bar\alpha_t}\, \epsilon\) is just a particular curved path between \(x_0\) and noise. Conversely, a flow-matching velocity field can be converted into a score, and vice versa, via the relationship \(\nabla \log p_t(x) = -\frac{1}{\sigma_t^2}(x - \sqrt{\bar\alpha_t}\, \mathbb{E}[x_0 \vert x_t])\).
Why flow matching is winning in practice. With straight paths, integrating the ODE for ~10 steps already reaches data quality; with diffusion’s curved paths, you typically need 50+ steps for the same fidelity. The training objective is also simpler: no \(\bar\alpha_t\) schedule, no signal-to-noise weighting tricks. Recent video models — Cosmos-Predict2, Wan2.1, and Fast-WAM — all use flow matching for these efficiency reasons. The whole “iterative video denoising” cost in imagine-then-execute WAMs is fundamentally a flow-matching ODE integration, and Fast-WAM’s central question — do we need to integrate this ODE at test time? — only makes sense once you see flow matching as the underlying machinery.
The geometric picture is the cleanest way to see the difference. Plot noise and data as two endpoints in some abstract space; each formulation traces a different trajectory between them, and that trajectory’s curvature is precisely what determines how many integration steps you need at sampling time. The figure below draws both paths in 2D and lets you slide \(t \in [0, 1]\) to watch the moving point and its velocity arrow on each.
From World Model to Action Model
从世界模型到动作模型
The Joint Distribution and Three Design Axes
联合分布与三个设计维度
A latent video diffusion model parameterizes \(p_\theta(z_{1:T} \vert o, l)\), where \(o\) is the conditioning observation, \(l\) is a language instruction, and \(z_{1:T}\) are latent frames produced by a spatiotemporal VAE. To turn this into a policy, we need to model
\[p_\theta(a_{1:H}, z_{1:T} \vert o, l)\]where \(a_{1:H}\) is an action chunk of horizon \(H\). There are essentially three design axes:
- Where do actions live? Are they an extra “modality” inserted into the same diffusion sequence (Cosmos Policy), or do they live in a separate expert head that attends to the video stream (Fast-WAM)?
- What does the joint loss factorize into? \(p(a, s' \vert s)\), \(p(s' \vert s, a)\), \(p(V(s') \vert s, a, s')\), etc. Different factorizations supply different gradients.
- What runs at test time? Generate the future and read off actions (imagine-then-execute), or skip future generation entirely (action-only forward pass)?
The two papers below sit on different points of these axes.
World Foundation Model vs World Action Model
世界基础模型 vs 世界动作模型
The framing. Cosmos brands itself as a World Foundation Model (WFM), not a World Action Model (WAM), and the choice is deliberate rather than cosmetic. A WFM is action-agnostic: it is pretrained purely on video — given some context (text, an image, a short clip), predict the future video. There is no action loss, no robot embodiment, no policy in the training objective. NVIDIA’s Cosmos paper (2025) positions the model as the video analog of an LLM foundation model: one large pretrained backbone over a massive video corpus, then a zoo of fine-tunes for specific downstream tasks.
WAM is downstream. A “World Action Model” is one of those downstream specializations: it predicts or generates actions, conditioned on observations, with an action loss in the training objective. Cosmos Policy is the WAM-shaped fine-tune of the Cosmos-Predict2 WFM — the backbone is reused, but the latent-slot layout is repurposed so that some slots carry actions and value, and the loss now includes action prediction. Fast-WAM is also a WAM by this definition: its “video” branch is a co-training auxiliary, but the main inference output is actions. The clean two-part test for “is this a WAM?” is (a) does the inference graph emit actions, and (b) is the action loss in the training objective?
Why the distinction matters. A WFM is what you scale — it gets the foundation-model treatment of “more data, more compute, more parameters”. A WAM is what runs on a robot — its capability ceiling is set by its WFM backbone, but the deployment characteristics (latency, accuracy, sample efficiency) are determined by the WAM-side design choices: latent layout, masking pattern, whether actions live in the main sequence (Cosmos Policy) or in a separate expert (Fast-WAM), and what runs at test time. Cosmos Policy and Fast-WAM are two points in WAM design space; in principle either could sit on top of any sufficiently capable WFM. Calling Cosmos itself a “WFM” rather than a “WAM” reserves the WFM label for the generic video pretraining and lets each downstream task — policy, simulator, evaluator, planner — claim its own model name.
Cosmos Policy: Latent-Frame Injection on Cosmos-Predict2
Cosmos Policy:在 Cosmos-Predict2 上的潜帧注入
Cosmos Policy’s distinguishing choice is one backbone, many slots. It takes a pretrained 2B Cosmos-Predict2 video DiT, leaves the architecture untouched, and post-trains it by repurposing some of the latent slots to carry actions, proprioception, and value instead of pure video. The same DiT then handles policy, world model, and value prediction by switching which slots are masked clean vs noised. The next three subsections walk through the latent layout, the joint loss, and what the inference graph looks like in the two deployment modes.
Architecture: One Sequence, Many Modalities
架构:一条序列,多种模态
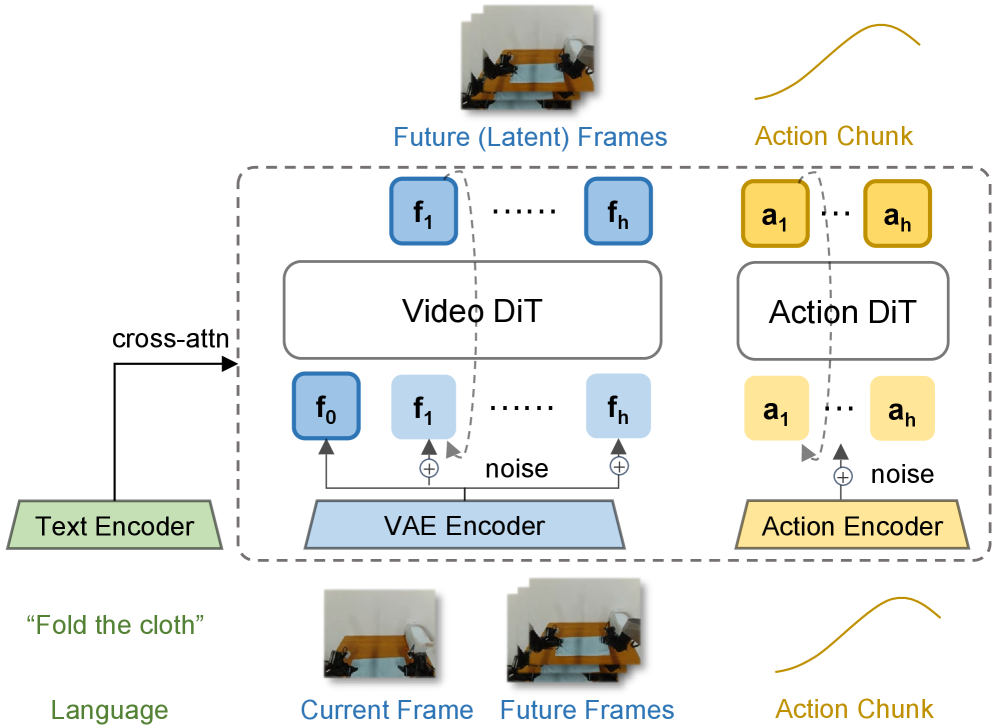
Before walking through what Cosmos Policy adds, it helps to anchor on what the base Cosmos-Predict architecture looks like. The figure below — reproduced from the Cosmos World Foundation Model paper (NVIDIA 2025) — shows the standard text-to-video DiT pipeline that Cosmos Policy fine-tunes: a Cosmos-Tokenize1 spatiotemporal VAE encodes the input video into latent tokens, Gaussian noise is added, and the tokens flow through 3D patchify and a stack of (N) DiT blocks. Each block follows the adaLN-Zero recipe — Self-Attention → Cross-Attention → MLP, with Scale/Shift/Gate driven by the time step (t) — plus T5-XXL text cross-attention. The denoised tokens are decoded back to pixels by the same VAE.
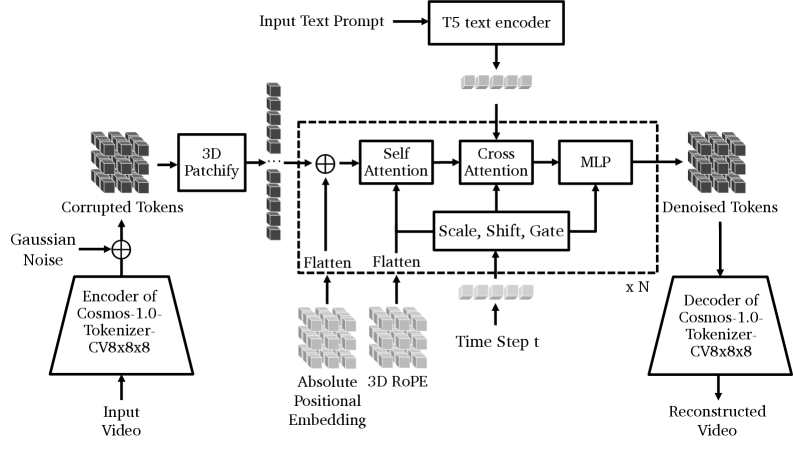
The base model is Cosmos-Predict2-2B, a flow-based latent video diffusion transformer using the Wan2.1 spatiotemporal VAE and an EDM denoising objective. Cosmos Policy’s design choice is deliberately conservative: no new architectural components. Instead, every additional modality is encoded as a latent frame and inserted into the diffusion sequence.
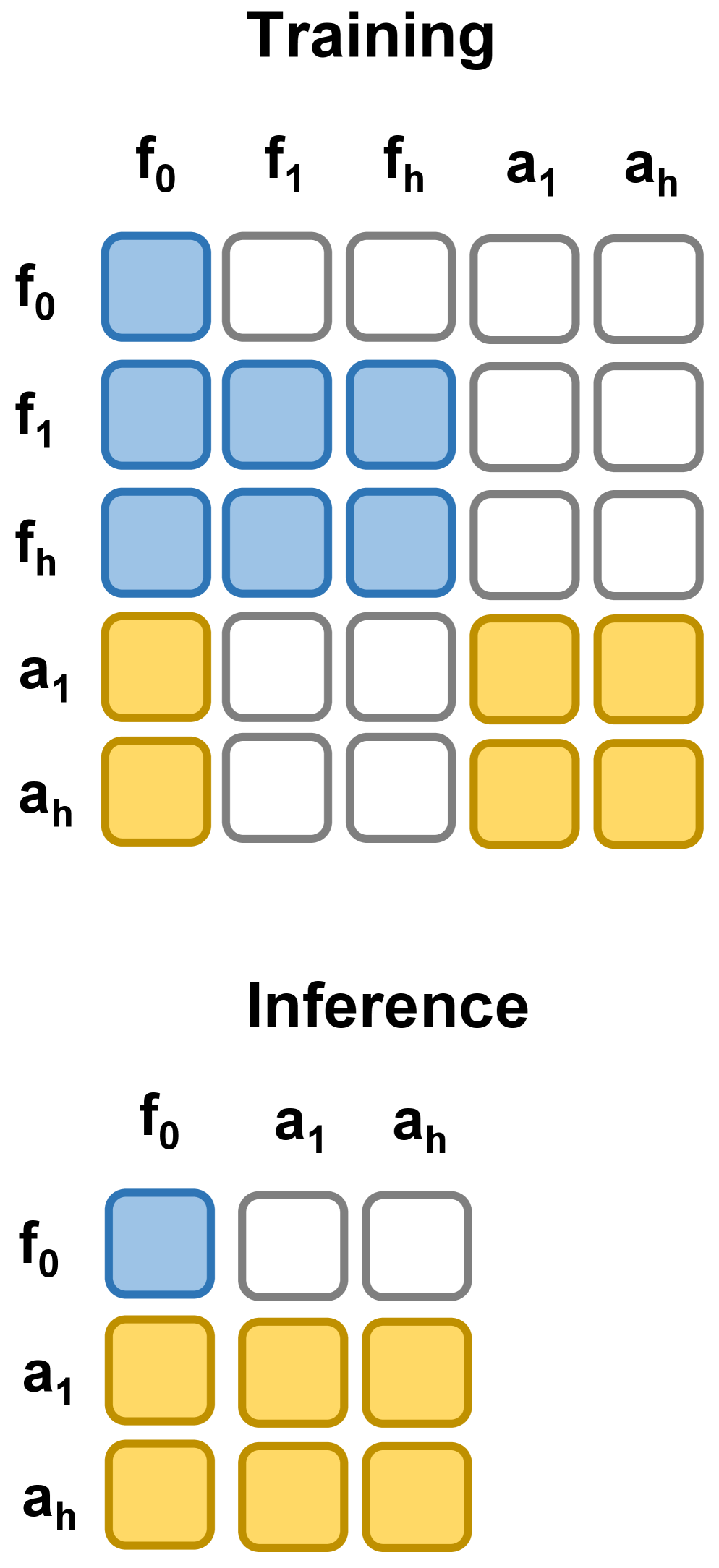
For a multi-camera robot, the sequence carries 11 latent frames:
\[\underbrace{[\text{blank}]}_{\text{placeholder}} \;\Vert\; \underbrace{[s^{\text{prop}}, s^{\text{wrist}}, s^{\text{3rd}}_{1,2}]}_{\text{current state }s} \;\Vert\; \underbrace{[a_{1:H}]}_{\text{action chunk}} \;\Vert\; \underbrace{[s'^{\text{prop}}, s'^{\text{cam}}_{1,2}]}_{\text{future state }s'} \;\Vert\; \underbrace{[V(s')]}_{\text{value}}\]Everything — proprioception, wrist and third-person camera frames, the action chunk, the predicted future state, and a learned value head — is denoised under the same diffusion transformer. The action chunk gets its own latent slot but is structurally indistinguishable from a video frame; the model’s attention machinery, positional encodings, and noise schedule are reused as-is.
This is a strong stance on representation: actions, observations, and values are all “frames” in the same latent video, and any factorization is induced by which frames are clean vs. noisy at inference.
The first thing to nail down is how a robot’s heterogeneous inputs — RGB cameras, joint angles, action vectors, scalar values — all end up looking like the same kind of object inside the model. The figure below traces each modality’s pathway: RGB goes through the pretrained Wan2.1 VAE, while every scalar stream just gets normalized and tile-broadcast into a \(H' \times W' \times 16\) volume. The point is the convergence at the right column — every input lands at the identical shape.
Once every modality is the same shape, “what task am I doing” reduces to “which slots are clean vs noised.” The figure below makes this concrete: the 11-slot layout stays fixed, and three different masking patterns turn the same backbone into a policy, a world model, or a value head. Click any of the training-mode buttons to see the corresponding mask, and watch which gradient term in the update equation lights up.
Joint Training: Three Factorizations in One Batch
联合训练:一个 batch,三种分解
A single batch is split across three conditional factorizations. With \(s\) the current state, \(a\) the action chunk, and \(s'\) the resulting state:
- 50% — policy: \(p_\theta(a, s', V(s') \vert s)\), trained on demonstrations.
- 25% — world model: \(p_\theta(s', V(s') \vert s, a)\), trained on rollouts.
- 25% — value model: \(p_\theta(V(s') \vert s, a, s')\), trained on rollouts.
Each factorization is implemented by clamping the corresponding latent frames to clean (zero noise) and noising the rest. Because the network is the same diffusion transformer, the three losses share gradients — the policy benefits from gradients computed on rollout-only world-model and value-model objectives.
Two practical knobs matter:
- The default Cosmos noise distribution (log-normal) is replaced with a 70/30 hybrid log-normal–uniform split, biasing samples toward higher noise levels — the regime where the model has to actually predict, not just denoise a near-clean image.
- Inference noise lower bound is raised from \(\sigma_{\min}=0.002\) to \(\sigma_{\min}=4\), terminating denoising early. Combined with parallel decoding of all latent slots, this lets the policy run in 5 denoising steps on LIBERO/RoboCasa.
What "Shared Gradients" Means Here
这里的"共享梯度"是什么意思
“Shared gradients” is shorthand for parameter sharing. The three losses are not literally the same gradient vector — they compute different things on different batch subsets. What is shared is the set of parameters \(\theta\) that all three gradients update:
\[\theta \leftarrow \theta - \eta \big(\nabla_\theta \mathcal{L}_{\text{pol}} + \nabla_\theta \mathcal{L}_{\text{wm}} + \nabla_\theta \mathcal{L}_{\text{val}}\big)\]Why it matters: if the three objectives ran on three separate networks, rollout-only gradients (\(\mathcal{L}_{\text{wm}}, \mathcal{L}_{\text{val}}\)) would only improve their own networks and give the policy nothing. Because Cosmos Policy stuffs all three factorizations into a single diffusion transformer — switched only by which latent frames are clamped clean vs. noised — the visual and dynamics features learned on rollout data flow directly into the policy backbone. The policy ends up training on 100% of the data: 50% demonstrations directly, 50% rollouts indirectly through shared representations.
This is standard multi-task learning, but Cosmos Policy takes it to an extreme: even “which task am I doing” is encoded purely in the noise pattern over latent slots; the network itself is task-agnostic.
Inference: Direct Mode and Planning Mode
推理:直接模式与规划模式
Cosmos Policy runs in two modes:
- Direct mode — clamp the current state \(s\) to clean, parallel-denoise the action, future state, and value slots. No VAE decoding — the future state is consumed in latent space only. ~5 denoising steps; real-time on a single GPU.
- Planning mode — sample \(N\) action proposals; for each, autoregressively predict \(s'\) and \(V(s')\); pick the proposal with the highest predicted value. This is best-of-\(N\) planning inside a single foundation model. With 3 future-state predictions × 5 value predictions per proposal, end-to-end latency is ~5 s per chunk.
Empirically, planning mode buys +12.5 points on the harder ALOHA tasks but is overkill on LIBERO/RoboCasa, where direct mode already saturates. Headline numbers:
| Benchmark | Cosmos Policy | Prior best |
|---|---|---|
| LIBERO (4 suites avg) | 98.5% | CogVLA 97.4% |
| RoboCasa (24 tasks, 50 demos) | 67.1% | Video Policy 66.0% (300 demos) |
| ALOHA real (4 tasks avg) | 93.6 | \(\pi_{0.5}\) 88.6 |
Ablations: removing auxiliary losses costs 1.5%; training from scratch (no Cosmos-Predict2 init) costs 3.9% on LIBERO — so most of the lift is post-training, not pretraining, but pretraining is not free either.
Fast-WAM: Imagine During Training, Not at Test Time
Fast-WAM:训练时想象,测试时不想象
Fast-WAM takes a different stance. Instead of one DiT handling everything, it splits video and action into two experts coupled by a single shared attention layer, and asks whether the video branch needs to actually run iterative denoising at test time at all. The answer is: train it as a co-training auxiliary, then drop the future-video denoising loop at inference. The five subsections below cover the motivating question, the Mixture-of-Transformer architecture, the inside of “shared attention”, the single-pass inference graph, and the ablation that decides between the three WAM paradigms.
The Question: Is Test-Time Imagination Actually Useful?
问题:测试时的想象是否真的有用?
Most prior WAMs (UniVLA, WorldVLA, and Cosmos Policy in its planning mode) follow an imagine-then-execute pipeline: at every action step, run iterative video denoising to hallucinate future frames, then read off (or condition on) actions. The runtime cost of denoising a future video is the dominant inference bottleneck — typically several hundred milliseconds to seconds per chunk.
Fast-WAM’s central question is uncomfortably basic: do we actually need the imagined video at test time, or is it only useful during training as a representation-learning auxiliary?
The paper draws a clean taxonomy of WAM paradigms before introducing its own. The figure below — Figure 1 of the Fast-WAM paper — contrasts the three: (A) joint-modeling WAMs that denoise video and action tokens together, (B) causal WAMs that first generate future observations and then condition action prediction on them, and (C) Fast-WAM, which keeps video co-training during training but skips the future-generation step at inference.
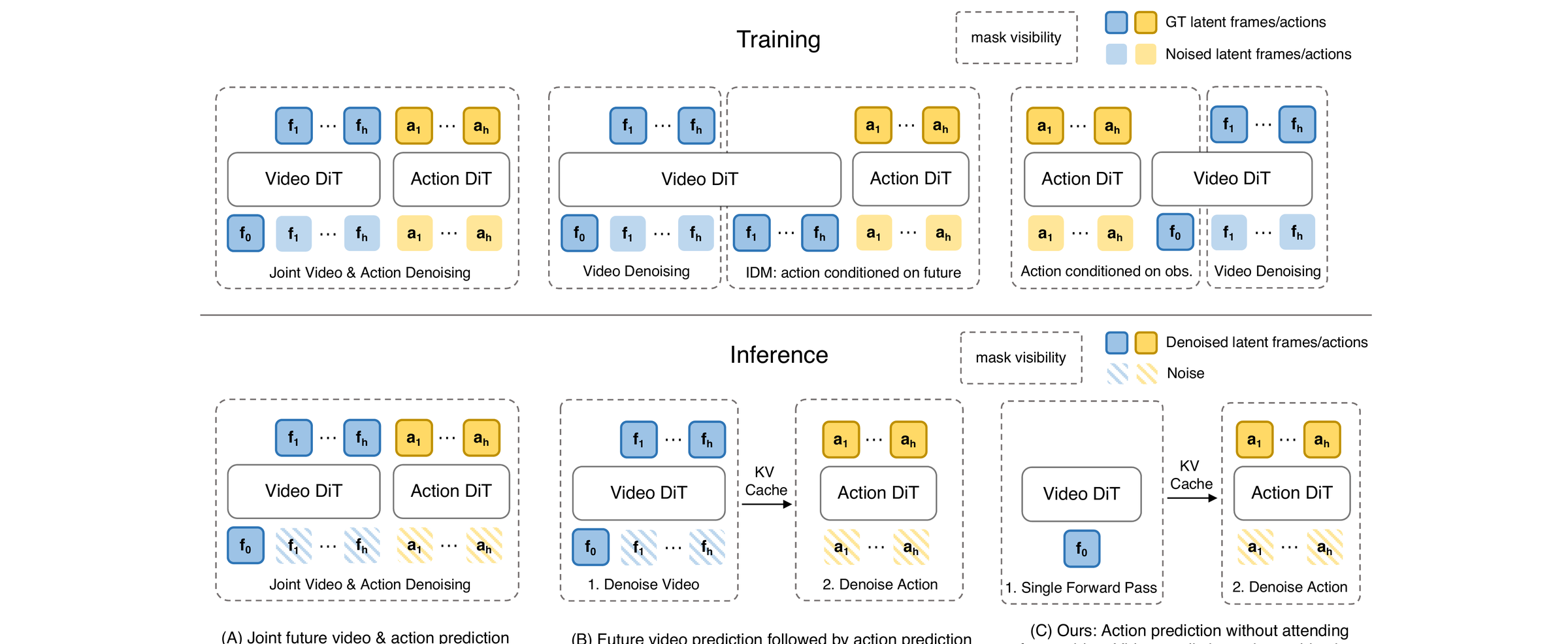
The three columns are worth walking through, because the rest of the section is structured as Fast-WAM’s argument against (A) and (B).
(A) Joint-modeling WAMs. Video and action are both denoising targets in a single diffusion process. One backbone denoises the concatenated \((z_{1:T},\, a_{1:H})\) sequence — at every denoising step \(\tau\), both the future-video latents and the action chunk are partially denoised, and they evolve together along one trajectory. Action tokens attend to (still-noisy) video tokens through joint attention, so the model refines actions based on a partially-imagined future. Symmetric coupling: action also influences video. Cost at inference: every action prediction needs a full multi-step denoise over both modalities — typically \(10\)–\(50\) steps, each step touching all video + action tokens. For a 9-frame future at 8×8 latent resolution this is by far the dominant compute. Cosmos Policy’s joint training is the closest representative of this stance (it uses three masking patterns over a single backbone rather than literal concatenation, but the spirit — one DiT, both modalities denoised together — is the same).
(B) Causal WAMs. Inference is split into two stages with a clean causal direction: stage 1 is a video diffusion model that denoises \(z_{1:T}\) from noise into clean future frames conditioned on the current observation \(o\) and language \(l\); stage 2 is a (typically much smaller) action policy that takes the generated future frames as extra context and produces \(a_{1:H}\), usually in a single pass or a small handful of steps. The “execute” stage is cheap; the “imagine” stage is not. Information flow is one-way: video → action, never action → video. Cost at inference: dominated by stage 1’s full video denoise; stage 2 adds only a small fixed overhead. Representatives: UniVLA, WorldVLA — and Cosmos Policy’s planning mode is also a Causal WAM (it imagines future frames in a first denoising pass and then reads off actions).
Why does the IDM training cell look different from its inference cell in the figure? Because training has a luxury inference does not: the real future frames sit in the dataset. So at training time the action head is conditioned on clean ground-truth future frames — a supervised inverse-dynamics task (“given \(o\), \(o'\), what action \(a\) produced this transition?”) — while the video DiT is separately trained to denoise future frames from noise. At inference the GT future is gone (the agent has to act to produce that future), so stage 1 has to hallucinate the future by iterative denoising, and only then can the action head read off frames. Training conditions on real futures; inference conditions on generated ones. This asymmetry is the structural weakness of IDM-style WAMs: the action head only ever saw clean GT futures during training, but at deployment it sees diffusion-generated futures that may be subtly off. It is also why inference is unavoidably expensive — you cannot shortcut the future-generation step, because the action head was never trained to be robust to a bad future.
(C) Fast-WAM. Training looks like (A): both the action flow-matching loss and the video flow-matching loss are active, and the shared attention carries gradient between branches. But at inference the video pathway runs once on the clean first observation only, and the future-video denoising loop is skipped entirely. The 1B action expert is the only thing that iterates (10 steps, CFG = 1.0). Information flow at deployment is asymmetric: the video branch is a fixed key/value bank, the action expert queries it. Cost at inference: one cheap clean pass through the 5B video DiT plus 10 cheap action denoising steps — the paper reports 190 ms total, ~4× faster than (A)- or (B)-style baselines. The bet: whatever the world model has learned has already left its imprint on the shared attention parameters by the time training ends; re-rolling out video at test time is paying twice for the same insight.
A note on layout: in (C), Action DiT is on the left at training but on the right at inference — left/right means different things in each row. Training is parallel (both branches run together, sharing attention), so left-right is just “which loss owns which branch”. Inference is serial (video DiT runs once → K/V cache → action DiT iterates), so left-to-right is execution order. And the actual difference between (A) and (C) is that (A) joint-trains the two as one denoising system over \((z, a)\), while (C) does not — in (C) action is the primary task and video is a parallel co-training auxiliary, not a joint diffusion target.
So the figure is really one axis — where in the lifecycle does video denoising happen? In (A) and (B) it happens at every test-time action step; in (C) only at training. The whole empirical contribution of the paper is the head-to-head comparison against (A)- and (B)-style ablations, holding the data and backbone fixed (see the decisive ablation below).
Architecture: MoT with Video DiT and Action Expert
架构:MoT,视频 DiT 加动作专家
Fast-WAM uses a Mixture-of-Transformer (MoT): a 5B-parameter video DiT and a 1B-parameter action expert DiT, coupled by shared attention — the two experts run their own MLPs and norms but attend to a common token sequence. Inputs are partitioned by modality:
- Video tokens flow through the video DiT.
- Action tokens flow through the action expert.
- Both attend to each other through shared attention.
The training objective is a joint flow-matching loss
\[\mathcal{L} = \mathcal{L}_{\text{act}} + \lambda\, \mathcal{L}_{\text{vid}}, \qquad \mathcal{L}_{\text{FM}}(y) = \mathbb{E}\big[\Vert f_\theta(y_t, t, o, l) - (\epsilon - y) \Vert_2^2\big]\]with \(\mathcal{L}_{\text{act}} = \mathcal{L}_{\text{FM}}(a_{1:H})\) on action chunks (horizon \(H = 32\)) and \(\mathcal{L}_{\text{vid}} = \mathcal{L}_{\text{FM}}(z_{1:T})\) on future video latents (9 frames after 4× temporal downsampling).
Inside the Shared-Attention Block
共享注意力块内部
The phrase “shared attention” is doing a lot of work in the architecture description above. The mechanic, concretely, is attention is shared but everything else is per-modality. Each MoT block does this:
-
Per-modality input projections. Video tokens \(x^v\) and action tokens \(x^a\) each go through their own QKV projection matrices: \(Q^v = x^v W_Q^v\), \(K^v = x^v W_K^v\), \(V^v = x^v W_V^v\), and similarly \((Q^a, K^a, V^a)\) from \(x^a\) via \(W_{Q,K,V}^a\). Each modality first lands in its own subspace.
-
Concatenate, then attend jointly. The Q, K, V tensors are concatenated along the sequence dimension into one combined Q, K, V, and standard self-attention runs on the combined sequence:
A video token’s query attends to both video and action keys/values; an action token’s query attends to both as well. This is the only operation that mixes modalities.
- Split back, apply per-modality output side. The attention output is split back along the sequence dimension into video-shaped and action-shaped outputs, each of which goes through its own output projection \(W_O^v\) or \(W_O^a\), residual connection, LayerNorm, and MLP. Block ends.
So “shared” = a single attention computation pools both modalities’ Q/K/V; “not shared” = everything outside the attention math (input projections, output projection, LayerNorm, MLP) is duplicated per modality.
The figure below draws one MoT block end-to-end with the per-modality (pink) and shared (blue) parts labeled separately. Read it bottom-to-top: video and action tokens enter, each goes through its own QKV projection, the resulting Q / K / V tensors are concatenated, one shared softmax computes attention over the joint sequence, the output is split back per modality, and each side runs through its own output projection / FFN / LayerNorm before exiting. The MoT paper (Liang et al. 2024) calls this design modality-aware sparsity; the actual “shared” piece is just the scaled-dot-product softmax in the middle.
It’s worth seeing what shared attention contains in self-attention vs cross-attention terms. The single softmax is implementing all four information flows at once:
- Video → Video (self-attention on video tokens)
- Action → Action (self-attention on action tokens)
- Video → Action (action queries reading video K/V — the cross-attention this post calls out earlier)
- Action → Video (video queries reading action K/V — the other direction of cross-attention)
In a vanilla design you would need separate self-attention layers per modality plus a separate cross-attention layer per direction — four sub-layers, four sets of weights. MoT folds all four into one softmax.
Why MoT instead of simpler alternatives?
- vs. one big self-attention with a shared MLP: would force video and action representations to share the same MLP subspace, which empirically hurts because the two modalities have very different statistics (image patches vs joint angles).
- vs. two separate transformers connected by cross-attention layers: doubles the attention cost (one self + one cross per side) and adds explicit “now run cross-attention” boundaries.
- vs. MoE (Mixture-of-Experts): MoE routes tokens to experts via a learned gate (with load-balancing losses, router instabilities, etc.). MoT uses a fixed assignment based on which modality the token belongs to — no router, no balancing loss, simpler training.
The implication for inference. Because attention is the only place the two modalities meet, the action expert’s queries can attend to the video expert’s K/V as long as that K/V is available — it does not require the video expert’s MLP to actually run again. This is what makes the KV cache trick work at inference: the video DiT’s K/V is computed once on the clean first observation, then the 1B action expert iterates 10 denoising steps, each step pulling from the cached video K/V via the same shared-attention softmax.
Figure 2 of the paper makes the MoT layout and the train/inference mask split explicit. Panel (a) shows how video tokens and action tokens flow through their respective DiT experts while sharing a single attention pool; panel (b) shows the masks — at training all video tokens are noised so the video loss is alive, while at inference the first observation frame stays clean and no future video is denoised.
Inference: A Single Clean Forward Pass
推理:一次干净的前向
At test time, Fast-WAM does not denoise any future video tokens. It keeps only the clean latent tokens of the first observation frame, runs them through the video DiT once (no iterative denoising of \(z_{1:T}\)), and lets the action expert denoise the action chunk with 10 steps and CFG scale 1.0. The video pathway provides representations; the action pathway provides actions; nothing else is materialized.
This is the key efficiency win. On real-world towel folding:
| Variant | Latency | Success |
|---|---|---|
| Fast-WAM (no test-time imagination) | 190 ms | ~40% |
| Fast-WAM-IDM (imagine-then-execute) | 810 ms | ~50% |
| Without video co-train | 190 ms | 10% |
The 4.3× latency reduction is the headline; the 10% success without video co-training is what justifies keeping it during training.
The Decisive Ablation
决定性消融
The clean experimental design is what makes Fast-WAM’s claim land. Three controlled variants:
- Fast-WAM — video co-training during training, no test-time imagination.
- Fast-WAM-Joint — joint denoising of video and actions at both train and test.
- Fast-WAM-IDM — generate video first, then action via inverse-dynamics model.
- No video co-train — pure action expert, no \(\mathcal{L}_{\text{vid}}\) at all.
Results:
| Variant | RoboTwin | LIBERO |
|---|---|---|
| Fast-WAM | 91.8% | 97.6% |
| Fast-WAM-Joint | 90.6% | 98.5% |
| Fast-WAM-IDM | 91.3% | 98.0% |
| No video co-train | 83.8% | 93.5% |
The gap between Fast-WAM and the imagine-then-execute variants (Joint, IDM) is within 1.2% — i.e., test-time imagination is essentially free to skip. The gap between Fast-WAM and the no-video-co-train baseline is 8.0% on RoboTwin and 4.1% on LIBERO. Conclusion: video prediction’s value is in the gradient, not in the rendered frames.
For comparison, LingBot-VA (a model with embodied pretraining) hits 92.2% on RoboTwin and 98.5% on LIBERO. Fast-WAM lands within ~1% of that without any embodied pretraining at all.
Comparing Cosmos Policy and Fast-WAM
Cosmos Policy 与 Fast-WAM 对比
With both architectures on the table, two side-by-side comparisons are worth pulling out — first a mechanical one (where the KV cache lives, and why one design is 4× faster), then a philosophical one (the two stances on whether the world model should keep running at deployment).
KV Cache: Where the Latency Difference Lives
KV cache:延迟差异的来源
With both architectures on the table, one comparison is worth pulling out before the synthesis: do either of these systems use KV cache sharing at inference, and where does it help? Neither paper names it as a headline optimization, but the two architectures admit it to very different degrees, and the difference is most of the reason Fast-WAM is so much faster.
The trick is: compute keys and values once on tokens that don’t change, then reuse them across many forward passes where something else changes. In autoregressive LLMs the “something else” is the next decoded token, and the cache covers the prefix. In diffusion DiTs the “something else” is the noised target tokens at each denoising step, and the cache covers any clean (unnoised) conditioning tokens — which, by definition, are identical at step \(\tau\) and step \(\tau-1\).
Cosmos Policy. All 11 latent slots go through one bidirectional DiT. At inference, some slots are clean conditioning (current state, language) and others are noised (action, optionally future). Across the 5 denoising steps the noised slots evolve but the clean slots don’t, so their K/V can be cached after the first step and reused. This is a standard inference optimization for any conditional diffusion DiT — the paper doesn’t market it, but the architecture admits it. In planning mode the saving is larger: phase 1 generates the imagined future frames, and in phase 2 those frames become clean conditioning, so phase 1’s full K/V can be carried into phase 2 and only the action slots need fresh computation.
Fast-WAM is the more striking case, and the cache opportunity is in fact what gives the paper its 4× latency win. The Mixture-of-Transformer design makes the entire video branch a one-shot conditioning forward pass at inference — the 5B video DiT runs once on the clean first observation frame and produces no future video at all. Only the 1B action expert iterates (10 denoising steps, CFG = 1.0). Because the shared attention pools Q/K/V from both branches, the video branch’s K/V is what the action expert reads at every step; computing it once and reusing it across all 10 action steps is exactly KV cache sharing applied at the expert boundary rather than at the step boundary. This is the structural reason Fast-WAM beats imagine-then-execute baselines on latency: not faster denoising, but no future denoising at all — the video branch becomes a fixed key/value bank that the action expert queries.
So the high-level contrast is:
- Cosmos’s KV cache lives inside one backbone — clean slots vs noised slots, same DiT, across denoising steps.
- Fast-WAM’s KV cache lives across two backbones — video expert produces, action expert consumes, all 10 action denoising steps reuse the same cache.
Both are special cases of the same underlying observation: clean conditioning is constant across denoising steps, so you should only pay for its K/V once.
A common follow-up: is the video DiT’s K/V also fed into the action DiT during training? In an information-flow sense yes, in a cache sense no. At every training step the video and action branches run together in a single forward pass, and the shared attention freshly pools both branches’ Q/K/V — so the action branch does read the video branch’s K/V, exactly the same way it does at inference. But there is no cache to speak of, because nothing is being reused: each training step sees a different example and a different sampled noise level \(\tau\), the video tokens are noisy (not clean) at training time, and there is no second forward pass that could read a stored cache. The KV cache trick is unique to inference because two conditions only line up there: the video tokens become clean (one shot, no denoising loop) and the action branch iterates over that same fixed video state for 10 steps. At training, neither condition holds — the video state changes every step and there’s only one pass per step — so caching saves nothing and would in fact be wrong (the cache from step \(n\) would be stale by step \(n+1\) because the video tokens have been re-noised at a different level).
The figure below steps through both flows side by side. Hit next (or play) to advance: Cosmos’s clean state slots fill the cache once and are read across 5 denoising steps; Fast-WAM’s video DiT runs once and feeds the action expert across 10 denoising steps.
Two Stances, One Take-Away
两种立场,一个共同启示
The two papers disagree about how much of the world model should run at deployment, but they agree on the underlying mechanism: the world prediction objective is what shapes useful representations.
| Cosmos Policy | Fast-WAM | |
|---|---|---|
| Backbone | Cosmos-Predict2-2B (single DiT) | MoT: 5B video DiT + 1B action expert |
| Action representation | Latent frame in same diffusion sequence | Separate expert with shared attention |
| Test-time future generation | Yes (planning mode) or No (direct mode) | Always no |
| Test-time latency | 5 steps (direct) / ~5 s (planning) | 190 ms |
| Embodied pretraining required | No (uses Cosmos pretraining) | No |
| Best benchmark numbers | LIBERO 98.5%, ALOHA 93.6 | LIBERO 97.6%, RoboTwin 91.8% |
Cosmos Policy bets that, with enough compute budget, running the world model at test time still pays off — the +12.5 pts on hard ALOHA tasks comes from the planning loop. Fast-WAM bets that for most tasks, the world model has already done its job by the time training ends, and pixel-space rollout at deployment is just expensive denoising.
The synthesis is probably: keep the video co-training loss everywhere, but make the inference-time pixel rollout optional and adaptive — cheap direct decoding when the action is obvious, planning when it isn’t. Neither paper closes that loop yet, but together they sketch the design space.